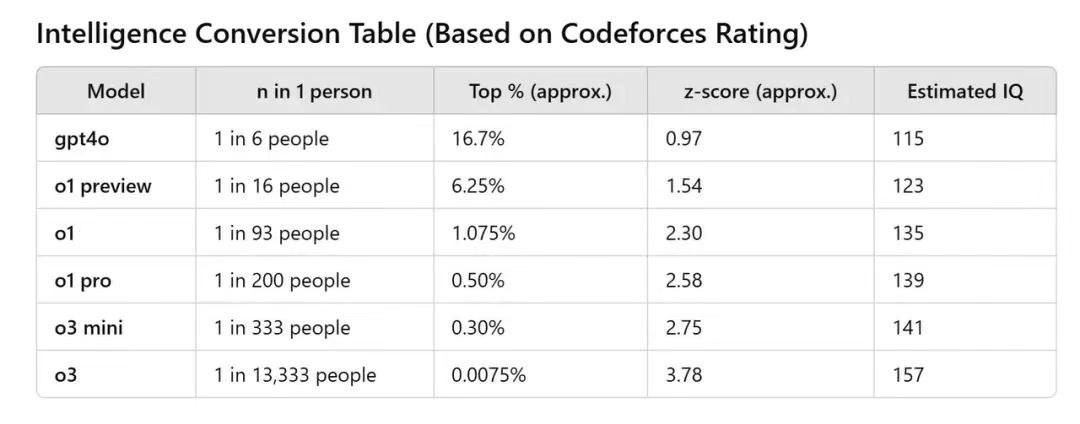
Çevrimiçi olarak yayılmış bir grafiğe göre, Openai’nin yeni Modeli O3, kodfores üzerinde 2727 puan aldı, bu da 157’lik bir insan IQ puanı – kesinlikle nadiren nadir bir başarı. Dahası, inanılmaz derecede, AI’s IQ GPT-4O’dan O3’e kadar sadece yedi ayda 42 puan arttı.
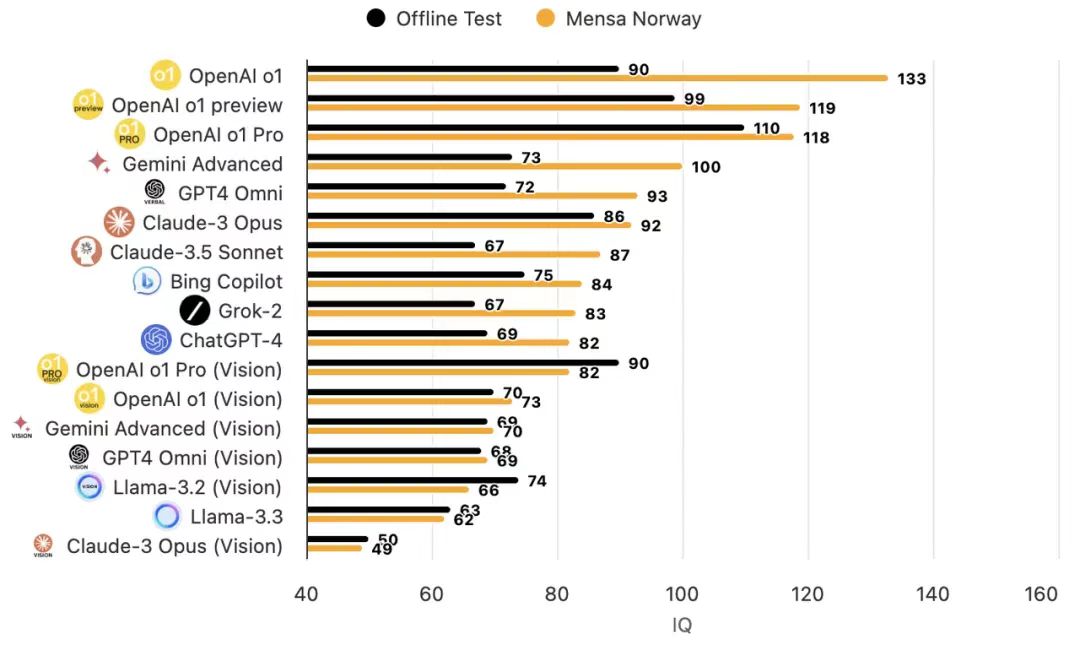
Son zamanlarda, Openai’nin O1 modeli, Mensa IQ testinde 133’e kadar puanlama için çok övüldü ve çoğu insanın IQ seviyelerini aştı.
Bununla birlikte, insanlığın AI’dan önceki yenilgisini ağıt yakmadan önce, daha temel bir soruyu düşünmeye değer: AI’yı özellikle insan IQ için tasarlanmış bir ölçek kullanarak ölçmek gerçekten uygun mu?
Akıllı AI ayrıca temel hatalar yapabilir
AI’da deneyimi olan herhangi bir kullanıcı, AI üzerinde insan IQ testleri yapmak mantıklı olsa da, önemli sınırlamalar olduğu sonucuna varabilir.
Bu sınırlama öncelikle testlerin doğal tasarımından kaynaklanmaktadır. Geleneksel IQ testleri, benzersiz insan düşünce kalıplarına dayanan, mantıksal akıl yürütme, mekansal farkındalık ve dil anlama gibi birçok boyutu kapsayan insan bilişsel yetenekleri için özel bir değerlendirme sistemidir. Açıkçası, yapay zekayı yargılamak için böyle bir “insan standardı” kullanmak metodolojik bir önyargıyı yansıtır.
İnsan beyni ve yapay zeka arasındaki farkları daha derinlemesine inceleyen bu önyargı daha da belirgin hale gelir. İnsan beyni yaklaşık 86 milyar nöron içerir, ancak araştırmalar sinaptik bağlantıların sayısının ve karmaşıklığının nöron sayısından daha önemli olabileceğini, insan beyninin kabaca 100 trilyon sinaptik bağlantısı olduğunu göstermektedir. Buna karşılık, 2023 yılında yayınlanan bir çalışma Doğa 1.76 trilyon parametre sayısı ile GPT-4’ün bile insan beyninden çok daha az karmaşık bağlantı modellerine sahip olduğunu gösterdi.
Bilişsel işleme açısından, insanlar yola göre düşünür: “Algısal giriş → Dikkat Filtreleme → Çalışma Bellek → Uzun Süreli Bellek Depolama → Bilgi Entegrasyonu.” AI sistemleri şunları takip eder: “Veri girişi → Özellik Çıkarma → Desen Eşleştirme → Olasılık Hesaplaması → Çıktı Kararı”, benzer görünen ancak temelde farklı.
Bu nedenle, insan bilişsel işlevinin belirli yönlerini taklit eden mevcut AI modellerine rağmen, aslında belirli algoritmalara dayalı bir olasılık makinesi olarak kalırlar ve tüm çıktılar giriş verilerinin programlı işlenmesinden kaynaklanır.
Son zamanlarda, Apple’dan bir araştırma makalesi, dil modellerinde gerçek bir resmi akıl yürütme yeteneği bulamayacaklarını kaydetti; Bu modeller daha çok karmaşık desen eşleşmesi ile uğraşıyorlar gibi davranırlar. Ayrıca, bu eşleşen mekanizma son derece kırılgandır – sadece bir adın değişmesi sonuçlarda yaklaşık% 10’luk bir varyansa yol açabilir. Ağaçları balıklara karşı tırmanma yeteneğini yargılamak, nihayetinde balığı aptal gibi hissettirir. Benzer şekilde, AI’nın insan standartlarına göre ölçülmesi yanıltıcı kararlara yol açabilir.
Örnek olarak GPT-4O’yu alın; IQ’nun 100 insan ortalama puanını çok aşabileceği görülebilir, ancak genellikle “AI halüsinasyonları” üreten 9.8 ve 9.11 arasında ayrım yapmak için mücadele eder. Openai, araştırmasında GPT-4’ün basit sayısal karşılaştırmaları ele almada hala temel hatalar yaptığını itiraf etti, bu da AI’nın “IQ” olarak adlandırılan gerçek zekadan ziyade sadece hesaplama yeteneğine daha yakın olabileceğini gösteriyor. Bu, DeepMind ve Yann Lecun’un CEO’sunun mevcut AI IQ’sunun bir kedininkinden bile daha düşük olduğu iddiaları gibi neden bazı aşırı ifadelerin ortaya çıktığını açıklamaya yardımcı olur – sert olsa da, içinde bir gerçeğin bir unsuru var.
Gerçekte, insanlık, ölçülmesi kolay ancak kapsamlı ve nesnel olan AI’nın zeka seviyesini ölçmek için uygun bir değerlendirme sistemi arıyor. Bunlar arasında en iyi bilinen Turing testidir. Bir makine tespit edilmeden insanlarla iletişim kurabilirse, akıllı kabul edilebilir. Bununla birlikte, Turing testi net kusurlara sahiptir: zekanın diğer önemli boyutlarını göz ardı ederken dilsel iletişim becerilerine çok fazla odaklanır.
Aynı zamanda, test sonuçları değerlendiricilerin kişisel önyargılarına ve yargı yeteneklerine büyük ölçüde güvenir; Turing testini geçen bir makine bile mutlaka gerçek anlayış veya bilinci gösteremez; Sadece insan davranışını yüzeysel düzeyde taklit ediyor olabilir.
Genellikle “IQ otoritesi” olarak kabul edilen Mensa testi bile, insanlar arasında belirli yaş grupları için uyarlanmış standart doğası nedeniyle AI için “gerçekçi” bir IQ puanı sağlayamaz.
Peki AI’nın halka ilerlemesini görsel olarak nasıl sergileyebiliriz?
Cevap, değerlendirme odağını AI’nın gerçek dünya sorunlarını çözme yeteneğine doğru kaydırmada yatmaktadır. IQ testleriyle karşılaştırıldığında, özel uygulama senaryoları için özel olarak tasarlanmış profesyonel değerlendirme standartları (kıyaslama testleri) daha anlamlı olabilir.
“Anlamak” dan “Yenilenen Cevaplara”, Test AI neden bu kadar zorlaştı?
Benchmark testleri, farklı boyutlardan çok çeşitli konuları kapsayabilir. Örneğin, GSM8K temel matematiği test ederken, matematik daha çok cebir, geometri ve hesap içeren rekabetçi sınavlara odaklanır. Humaneval Python programlamasını değerlendirir. Matematik ve bilimlerin ötesinde, AI, modellerin okuma pasajlarına dayalı karmaşık akıl yürütme yapmasına izin veren damla veri kümesi tarafından gösterildiği gibi “okuduğunu anlama” üzerinde de test edilmektedir. Buna karşılık, Hellaswag gerçek dünya senaryolarına bağlı sağduyulu akıl yürütmeyi vurgular.
Ancak, kıyaslama testleri genellikle ortak bir sorunla karşı karşıyadır. Test veri kümesi herkese açıksa, bazı modeller eğitim sırasında bu sorunları “önizlemiş” olabilir. Gerçek sınavdan önce, tam bir dizi sahte sınav, hatta gerçek soruları tamamlayan öğrencilere benzer; Sonuç olarak, son yüksek puanlar gerçek yeteneklerini doğru bir şekilde yansıtmayabilir. Bu senaryoda, AI’nın performansı sadece gerçek anlayış ve problem çözme yerine basit örüntü tanıma ve cevap eşleşmesinden kaynaklanabilir. Rapor kartı mükemmel görünse de, referans değerini kaybeder.
Dahası, sadece puanları karşılaştırarak, “sıralamaları manipüle etme” yönünde bir eğilim görüyoruz. Örneğin, en güçlü açık kaynaklı büyük model olarak lanse edilen yansıtma 70b’nin aldatıcı uygulamalarla uğraştığı ve birçok büyük model sıralamasının güvenilirliğine önemli ölçüde zarar verdiği bulunmuştur. Kötü uygulama olmasa bile, AI yetenekleri geliştikçe, kıyaslama test sonuçları genellikle bir “doygunluk” durumuna ulaşır.
DeepMind CEO’su Demis Hassabis’in önerdiği gibi, AI alanının daha iyi kıyaslama testlerine ihtiyacı var. İyi bilinen akademik kıyaslama testleri olsa da, biraz doymuş hale gelmişlerdir ve çeşitli üst modeller arasındaki ince farklılıkları etkili bir şekilde ayırt edemezler. Örneğin, GPT-3.5 MMLU’da 70.0 puan aldı, GPT-4 86.4 ve Openai’nin O1’i 92.3 puan aldı. İlk bakışta, bu, AI ilerlemesinin yavaşlama oranını gösteriyor gibi görünüyor, ancak aslında testin AI tarafından fethedildiğini ve modeller arasındaki güç farklılıklarının ölçülmesinde etkisiz hale getirildiğini yansıtıyor.
Sonsuz bir kedi ve fare oyunu gibi, AI bir değerlendirmeyle başa çıkmayı öğrendikten sonra, endüstri yeni değerlendirme yöntemleri aramalıdır. İki ortak yaklaşımı karşılaştırırken, biri kullanıcıların doğrudan tercihlere göre oy kullandığı kör testtir ve diğeri sürekli olarak yeni kıyaslama testleri getirilmesini içerir. Birincisi, insan tercihlerinin rekabetçi bir arenada modelleri ve chatbotları değerlendirdiği Chatbot Arena platformu tarafından örneklendirildi. Mutlak puanlar vermeye gerek yoktur; Kullanıcılar sadece iki anonim model karşılaştırırlar ve daha iyi olanı oylar.
Son zamanlarda, son zamanlarda spot ışığında, Openai tarafından getirilen ark-AGI testidir. Fransız bilgisayar bilimcisi François Chollet tarafından tasarlanan ARC-AGI, AI’nın soyut akıl yürütme yeteneklerini ve bilinmeyen görevler üzerindeki öğrenme verimliliğini özellikle AGI yeteneğini değerlendirmek için önemli bir standart olarak kabul eder. Bu görevler insanlar için kolaydır, ancak AI için oldukça zordur. ARC-AGI, her görevin birkaç giriş ve karşılık gelen çıktı ızgaraları sunduğu bir dizi soyut görsel akıl yürütme görevini içerir. Test denekleri bu örneklere dayanarak kuralları çıkarmalı ve doğru çıkış ızgaralarını üretmelidir.
Standart hesaplama koşulları altında O3, ARC-AGI’da% 75.7 puan alırken, yüksek hesaplama modunda% 87.5 puan aldı. % 85 puan insan normal seviyelerine yakındır. Bununla birlikte, Openai O3 mükemmel bir rapor kartı sunsa da, O3’ün AGI elde ettiğini kanıtlamıyor. François Chollet, X platformunda insanlar için kolay olan birçok Arc-AGI-1 görevinin O3 modeli için çözülemez kaldığını vurguladı. İlk göstergeler, ARC-AGI-2 görevlerinin bu model için hala oldukça zor olduğunu göstermektedir.
Bu, insanlar için basit ve eğlenceli, ancak yapay zeka için zor olan değerlendirme standartlarının oluşturulmasının gerçekten mümkün olduğunu göstermektedir. Bu tür değerlendirme standartlarını oluşturabildiğimizde, gerçekten yapay genel zekaya (AGI) sahip olacağız. Kısacası, insan tarafından tasarlanan çeşitli testlerde AI için yüksek puanlar elde etmek yerine, AI’nın insan toplumunun gerçek ihtiyaçlarına nasıl daha iyi hizmet edebileceğini düşünmek daha anlamlı olabilir; Bu, AI ilerlemesini değerlendirmek için en alakalı boyut olabilir.